Inside the Prediction Brain
How does the prediction brain work?

Background
The human brain is fascinating. It is highly efficient and uses very little energy to process, predict, and act. We are now trying to build a synthetic system that can imitate at least parts of that behavior. There are many researchers who understand this deeply, and I am not pretending to be one of them. I am sharing a practical mental model that helps me reason about LLMs. If you disagree with anything here, please use the contact form and let me know. I am still learning too.
In the previous article, we talked about LLMs as prediction engines. In this one, let’s open that engine and look under the hood.
The Prediction Engine
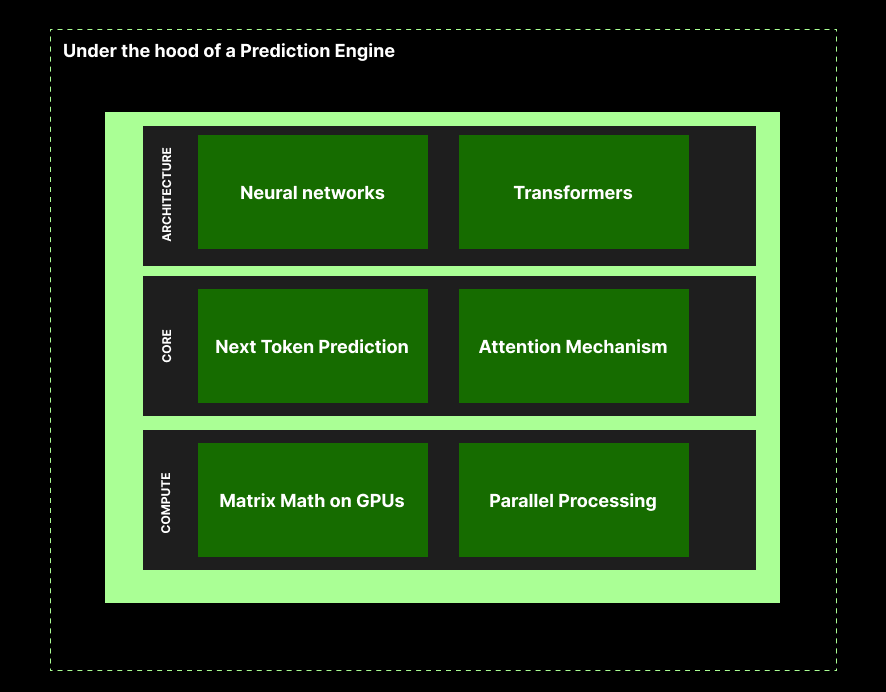
Three core layers
1) Architecture layer (The Structure)
This is the model design itself.
- Neural networks give us the basic learning framework.
- Transformers are the architecture that made modern LLMs practical at scale.
Think of this layer as the blueprint for how information flows and gets updated inside the model.
2) Core reasoning layer (The Mechanism)
This is where the “prediction brain” behavior happens.
- Next-token prediction is the main objective: given context, predict what comes next.
- Attention mechanism helps the model decide which earlier tokens matter most right now.
This pair is the heart of the system. It is why LLMs feel like they are “thinking” while actually running repeated prediction steps.
3) Compute layer (The Hardware)
This is the execution engine.
- Most of the work is large-scale matrix math.
- GPUs handle this efficiently because they are built for massive parallel processing.
Without this layer, modern model sizes and response speed would not be practical.
It’s all just numbers!
Underneath all of this, an LLM is billions of numbers organized in large matrices. Those numbers encode patterns in language, code, grammar, and whatever else was in the training data. It’s facinating and strange how human knowledge can be compressed to into numerical relationships. Next time, when you are using a chat app and it seems to empathize with you, remember, it’s just all numbers beneath the surface.
In the AI world, these are called parameters. GPT-4 for example contains roughly 1.8 trillion parameters. These parameters are tuned to ensure next word is predicted accurately. Facinating right?
If you want to visualize this, Brendan Bycroft has a made site for it.
Training vs using
It helps to separate two phases:
- Training time: massive data, large compute, gradient updates, and parameter tuning.
- Inference time: your prompt goes in, and the trained model predicts token by token.
Most of us interact only with inference, but model quality comes from the training phase and post-training alignment work.
How much power does this consume?
Training costs an enormous amount of power. Companies spend millions to train and fine-tune models.
For most of us, inference (each prompt you send) is what matters day to day. Energy use depends on the task: a short chat completion is tiny; image generation and long “reasoning” runs cost more.
The table below uses rough, order-of-magnitude figures from public estimates (including OpenAI’s ~0.34 Wh per average GPT-4o text query). The Switch column is a friendly comparison: if the Switch draws about 6–7 W while gaming, how long would that same energy run the console?

| Action | Energy (approx.) | Equivalent Switch playtime (approx.) |
|---|---|---|
| Standard GPT-4o text prompt | ~0.34 Wh | ~3.5 min |
| AI image generation prompt | ~1.20 Wh | ~12 min |
| Heavy reasoning prompt | ~33 Wh | ~5.5 hours (330 minutes) |
| Human brain | Cup of coffee | While playing the Switch |
Why code works so well?
Code has structure, patterns, and clear feedback loops. That makes it a strong domain for prediction systems:
- syntax is constrained
- examples are plentiful
- correctness can often be tested quickly
When a model sees many high-quality code examples, it gets much better at continuing patterns and composing useful functions.
Same applies to grammar correction, definition etc. where the training dataset is likely well known and accurate.
Why this feels different from older software?
With deterministic software, we expect exact behavior from exact rules. With prediction systems, we get behavior from patterns learned in data.
That creates new realities:
- output quality depends on context quality
- behavior can vary run to run
- guardrails and evaluation become first-class engineering concerns
This is why prompting, retrieval, evals, and tool use matter so much in real products.
Closing thought
The prediction brain is not human intelligence. It does not “understand” the world the way we do. But it is still incredibly useful when we frame problems correctly.
We are early. The patterns are forming fast. If we learn to combine deterministic systems with prediction systems thoughtfully, we can build products that were hard to imagine a few years ago.

References
These helped me build the mental model above. I am still learning. Treat them as starting points, not the final word.
- Deep Dive into LLMs like ChatGPT — Andrej Karpathy (YouTube) — End-to-end walkthrough of how modern chat models are built and used.
- The Illustrated Transformer — Jay Alammar — Visual explanation of attention and the transformer architecture.
- Attention Is All You Need (2017 paper) — Original transformer paper from Google researchers.
- Language Models are Few-Shot Learners (GPT-3 paper) — Shows scale and next-token prediction at the foundation of large language models.
Appendix
A slightly more technical section.
Why do transformers perform well?
Earlier sequence models (like many RNN-style setups) tended to process tokens one after another. Transformers changed the shape of the problem: with self-attention, much of the work can happen in parallel across the sequence. The model can relate words across a sentence (or chunk of text) in one pass instead of waiting for information to trickle through step by step. That parallelism is a big reason transformers scaled so well and why they became the default backbone for modern LLMs.
What is the attention mechanism?
Attention is how the model decides which parts of the input matter for the next prediction. Instead of only leaning on the word right next door, each token can look at (attend to) other tokens in the context near or far and weight them differently.
What is a context window?
The context window is how much text (how many tokens) the model can consider at once in a single forward pass - your prompt, prior chat history, retrieved documents, and so on. If your message is longer than the window, something has to be truncated, summarized, or moved out of scope.
Training and inference are different stories. Frontier models are trained on enormous GPU clusters. Reports often cite tens of thousands of accelerators, sometimes far more. That scale is about learning weights from huge datasets. The context window, by contrast, is a limit on what fits in memory and attention when you actually use the model. Bigger windows cost more compute per request; that is one reason serving long context chat is expensive.